多层感知机
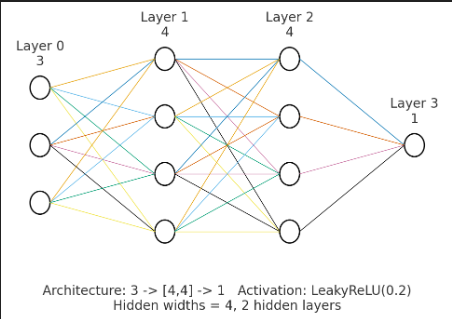
多层感知机 Multi-Layer Perceptron
一个定制化的、极简的“多层感知机”(Multi-Layer Perceptron, MLP),也就是通常说的全连接神经网络(Fully Connected Network)。
这种网络结构通常用于隐式神经表示(Implicit Neural Representation),类似于NeRF(神经辐射场)的简化版,用于将空间坐标映射为物理属性(这里是光照强度)。
模型规格和实现指南:
1. 模型架构
这是一个非常轻量级的回归(Regression)模型。
- 模型类型: 全连接神经网络 (MLP / DNN)
- 输入层 (Input): 3个神经元(对应局部坐标 $X, Y, Z$)
- 隐藏层 1 (Hidden Layer 1): 4个神经元
- 激活函数: Leaky ReLU ($\alpha = 0.2$)
- 隐藏层 2 (Hidden Layer 2): 4个神经元
- 激活函数: Leaky ReLU ($\alpha = 0.2$)
- 输出层 (Output): 1个神经元(对应亮度 Luminance)
- 总参数量: 极少(大约几十个参数),非常适合实时渲染。
2. 代码实现 (PyTorch 示例)
可以使用 PyTorch 编写如下代码:
import torch
import torch.nn as nn
class LightBakingNetwork(nn.Module):
def __init__(self):
super(LightBakingNetwork, self).__init__()
# 定义网络结构
# 输入: 3 (XYZ) -> 隐藏层1: 4
self.layer1 = nn.Linear(3, 4)
# 隐藏层1: 4 -> 隐藏层2: 4
self.layer2 = nn.Linear(4, 4)
# 隐藏层2: 4 -> 输出: 1 (Luminance)
self.output_layer = nn.Linear(4, 1)
# 激活函数: Leaky ReLU (斜率 0.2)
self.leaky_relu = nn.LeakyReLU(negative_slope=0.2)
def forward(self, x):
# 前向传播过程
x = self.layer1(x)
x = self.leaky_relu(x)
x = self.layer2(x)
x = self.leaky_relu(x)
# 输出层通常不加激活函数,或者根据归一化需求加Sigmoid/ReLU
# 如果光照值必须为正,可以在最后加一个 ReLU
prediction = self.output_layer(x)
return prediction
# 实例化模型
model = LightBakingNetwork()
# 打印模型结构以核对
print(model)3. 为什么使用这种简单的模型?
应用场景是图形学中的光照探针压缩。
- 目的: 不是为了“识别”物体,而是为了压缩数据。原本你需要存储成千上万个点的光照数据(占用大量内存),现在你只需要存储这个小网络的几十个参数(Float32),就能算出任意位置的光照。
- 拟合函数 : 神经网络本质上就是一个函数拟合器。通过训练,这个网络学会了在该 8米 体素内,哪个坐标是亮的,哪个坐标是暗的(比如屋檐下)。
- Leaky ReLU 的作用: 防止“神经元死亡”问题,且计算极其简单,适合在 GPU Shader 中实时运行。
- 单通道输出 (Luminance): 图片提到只输出亮度而不是 RGB。这是为了在极小的网络容量(宽度仅为4)下保证精度。如果输出 RGB,网络需要拟合 3 个值的变化,对于只有 4 个神经元的宽度的网络来说,负担太重,会导致结果模糊。
4. 如何训练(Training)
要得到结果,光有模型是不够的,关键在于数据:
- 数据准备 (Offline Baking): 你需要在渲染软件(如Blender, Unreal, Unity 或自研引擎)中,在这个 8米 的立方体内,密集地采样真实的光照值。
- Dataset =
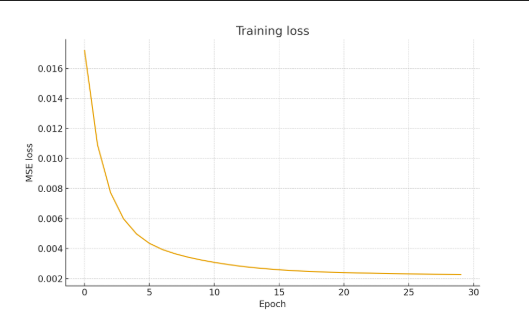
- 损失函数 (Loss Function): 通常使用 MSE (均方误差) 或 L1 Loss,让网络预测的光照值尽可能接近烘焙的真实值。
- 过拟合 (Overfitting): 在这种应用中,过拟合反而是好事。你想让这个网络完全“记住”这个特定体素内的光照分布。
总结
需要的就是一个极其简单的 3层 MLP(多层感知机)。这种技术在游戏工业界(如《使命召唤》或育碧的Irradiance Volume技术)经常被用来做光照数据的压缩和插值。
GPT:
实现要点(简短说明)
网络结构:输入 3 -> 隐藏层 4 -> 隐藏层 4 -> 输出 1(即 3→[4,4]→1)。
激活函数:LeakyReLU(negative_slope=0.2)(与你的文档一致)。
损失函数:MSE(均方误差)。
优化器:Adam,学习率 1e-3(演示用)。
训练数据:示例中我用了一个合成数据集(在 8m 立方体内随机采样 XYZ,并用一个简单规则产生“亮度”标签,包含一个模拟建筑遮挡的 region),以便演示训练流程。请用你烘焙出的真实 (XYZ, GI_Value) 数据替换合成数据进行正式训练。
如何在你本地/生产流程中使用(示例代码片段)
模型定义(和训练时一致)
import torch, torch.nn as nn
class SmallDNN(nn.Module):
def __init__(self, in_features=3, hidden=4, out_features=1, negative_slope=0.2):
super().__init__()
self.net = nn.Sequential(
nn.Linear(in_features, hidden),
nn.LeakyReLU(negative_slope=negative_slope),
nn.Linear(hidden, hidden),
nn.LeakyReLU(negative_slope=negative_slope),
nn.Linear(hidden, out_features)
)
def forward(self, x):
return self.net(x)
# 加载训练好的权重
model = SmallDNN()
state = torch.load("/path/to/small_dnn.pt", map_location="cpu")
model.load_state_dict(state)
model.eval()
# 用烘焙数据预测
import numpy as np
xyz = np.array([[0.2, -1.0, 0.5]], dtype=np.float32) # 示例
inp = torch.from_numpy(xyz)
with torch.no_grad():
lum = model(inp).numpy()
print("Predicted luminance:", lum)
训练建议(用于真实烘焙数据)
数据准备:把烘焙器得到的 (XYZ, GI_value) 组织成训练集。建议把 XYZ 标准化(例如把坐标从 [-4,4] 映射到 [-1,1] 或做均值/标准差归一化),GI_value 也可做归一化到 [0,1](或保持线性,取决于你的后处理)。
数据量:越多越好(尤其要覆盖建筑物内部与外部的不同遮挡区域)。
验证集:保留一部分作为验证集来观察过拟合。
超参调优:如学习率、批量大小、隐藏层宽度(若需要更高精度可尝试增宽到 8、16 等)、训练轮次等。
损失:如果你只关心亮度感知效果,也可以尝试 L1 损失或感知加权损失(视任务而定)。
输出:训练时只预测单通道亮度(如文档所述,不预测 RGB),能增强训练精度。