Ocean FFT
Ocean FFT 实现解析
参考实现: GodotOceanWaves - GitHub
在线演示: Ocean FFT Demo
本文将深入解析一个基于 WebGPU 的海洋模拟实现。该实现参考了 Godot 引擎的海洋渲染方案,通过快速傅里叶变换 (FFT) 在 GPU 上实时生成逼真的海洋波浪。
1. 整体架构概览
整个海洋模拟分为两个主要阶段:
- 计算阶段 (Compute Pass):使用 Compute Shader 在 GPU 上进行频谱生成、时间演化和 FFT 变换,最终输出位移贴图 (Displacement Map) 和法线/泡沫贴图 (Normal/Foam Map)。
- 渲染阶段 (Render Pass):使用生成的贴图对一个高密度网格进行顶点位移和像素着色,实现最终的水面效果。
核心特性:
- 级联 (Cascades):使用多个不同尺度的 FFT 纹理叠加,模拟从大浪涌到小波纹的多尺度细节。
- JONSWAP 频谱:基于真实物理的海洋频谱模型。
- 次表面散射 (SSS) 近似:模拟光线在水体内部的散射效果。
2. 计算阶段详解
2.1 频谱初始化 (Spectrum Compute)
第一步是根据风速、风向、吹程 (Fetch) 等物理参数,生成初始频谱 和其共轭 。
核心公式:TMA/JONSWAP 频谱
JONSWAP 频谱是一种经验公式,用于描述受风驱动的海浪能量分布:
其中:
- :Phillips 常数
- :峰值频率
- :峰值增强因子 (通常为 3.3)
WGSL 实现片段 (spectrumCompute.wgsl):
fn tma_spectrum(w : f32, w_p : f32, alpha : f32, depth : f32) -> f32 {
let beta = 1.25;
let gamma = 3.3;
let sigma = select(0.07, 0.09, w > w_p);
let r = exp(-pow(w - w_p, 2.0) / (2.0 * sigma * sigma * w_p * w_p));
let jonswap = (alpha * G * G) / pow(w, 5.0) * exp(-beta * pow(w_p / w, 4.0)) * pow(gamma, r);
// TMA 深度衰减
let w_h = min(w * sqrt(depth / G), 2.0);
let depth_attenuation = select(0.5 * w_h * w_h, 1.0 - 0.5 * pow(2.0 - w_h, 2.0), w_h > 1.0);
return jonswap * depth_attenuation;
}方向性波浪:Hasselmann 扩展函数
为了模拟风与波浪方向的关系,引入了 Hasselmann 方向性函数:
fn hasselmann(w : f32, w_p : f32, wind_speed : f32, swell : f32, theta : f32, wind_dir : f32) -> f32 {
let p = w / w_p;
let s = select(6.97 * pow(abs(p), 4.06), 9.77 * pow(abs(p), -2.33 - 1.45 * (wind_speed * w_p / G - 1.17)), w > w_p);
let s_xi = 16.0 * tanh(w_p / w) * swell * swell;
return longuet_higgins(s + s_xi, theta - wind_dir);
}频谱生成后,数据被存储到一个 rgba32float 纹理数组中:
rg通道:$H_0(k)$ 的实部和虚部ba通道:$H_0^*(-k)$ 的实部和虚部
2.2 时间演化 (Spectrum Modulate)
初始频谱 是静态的。为了让波浪动起来,需要根据时间 对其进行相位调制:
其中 是色散关系 (dispersion relation),$d$ 是水深。
WGSL 实现 (spectrumModulate.wgsl):
fn exp_complex(x : f32) -> vec2<f32> {
return vec2<f32>(cos(x), sin(x));
}
fn mul_complex(a : vec2<f32>, b : vec2<f32>) -> vec2<f32> {
return vec2<f32>(a.x * b.x - a.y * b.y, a.x * b.y + a.y * b.x);
}
@compute @workgroup_size(WORKGROUP, WORKGROUP, 1)
fn main(@builtin(global_invocation_id) gid : vec3<u32>) {
// ...
let mod_phase = dispersion(k, params.shape.x) * params.foamTime.x; // foamTime.x = time
let modulation = exp_complex(mod_phase);
let h = mul_complex(h0.xy, modulation) + mul_complex(h0.zw, conj_complex(modulation));
// ...
}这一步还会计算用于后续 FFT 的多个输入信号:
hx,hy,hz:X, Y, Z 方向的位移分量dhy_dx,dhy_dz等:梯度分量,用于法线和 Jacobian 计算
2.3 FFT 计算 (FFT Compute)
从频域转换到空间域需要执行 2D 逆傅里叶变换。本实现采用 Stockham FFT 算法,分为行变换和列变换两部分。
整体计算流程
频谱生成 → 时间调制 → FFT行变换 → 矩阵转置 → FFT列变换 → 解包 → 位移/法线贴图蝶形运算示意图 (8-point FFT)
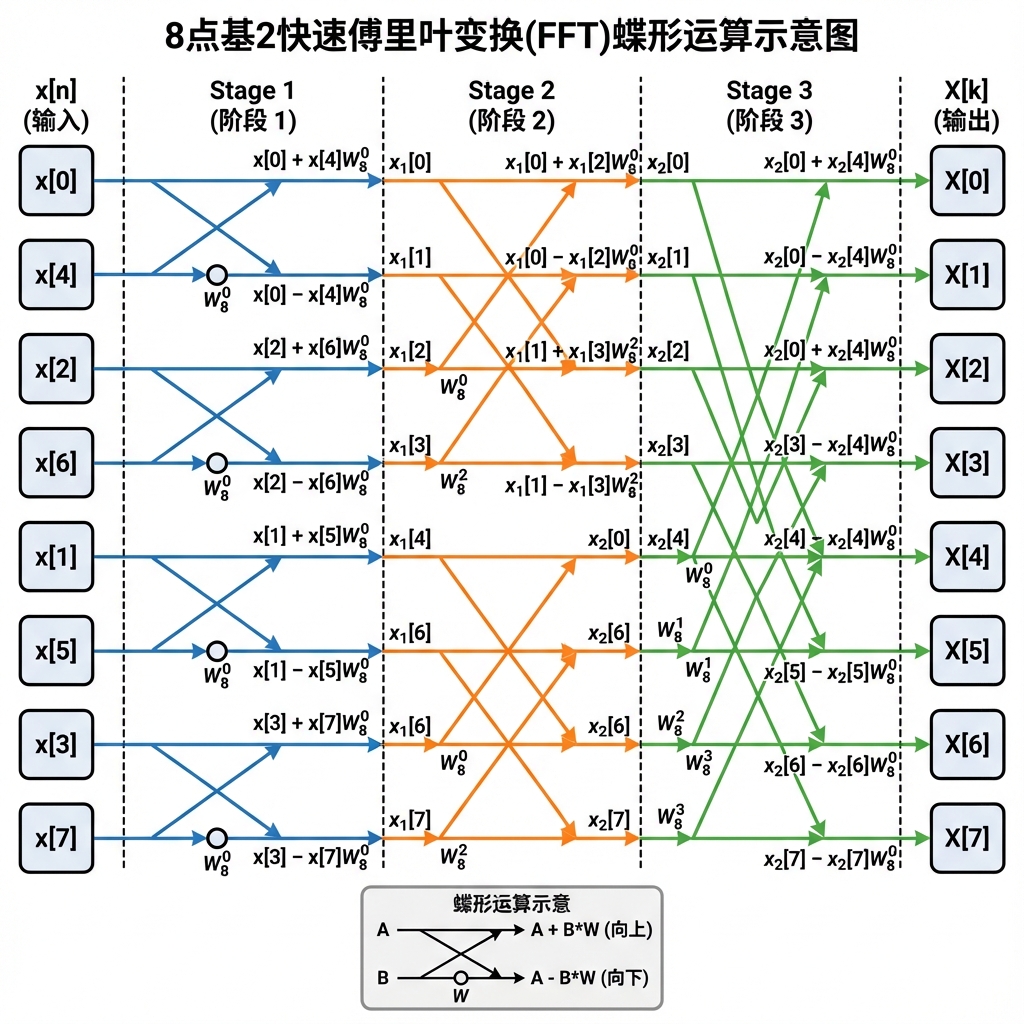
上图展示了 8 点 FFT 的蝶形运算结构。每个蝶形节点执行以下运算:
FFT vs IFFT 的关键区别
FFT 和 IFFT 的蝶形结构完全相同,唯一的区别在于旋转因子的符号:
- FFT 使用负号:W = cos(θ) - i·sin(θ)
- IFFT 使用正号:W = cos(θ) + i·sin(θ)
本实现中,旋转因子计算为
vec2(cos(θ), sin(θ)),即正号,所以虽然使用的是 FFT 的算法结构,但实际执行的是 IFFT(逆傅里叶变换),将频域数据转换到空间域。
蝶形因子预计算 (Butterfly Precompute)
Stockham FFT 的核心是"蝶形运算"。为了提高效率,蝶形运算的读取索引和旋转因子 (Twiddle Factor) 被预先计算一次,存储到 GPU Buffer 中,之后每帧的 FFT 直接查表使用,避免重复计算。
Butterfly 结构体存储了每个蝶形运算需要的信息:
| 字段 | 说明 |
|---|---|
readA |
蝶形运算的上输入索引(对应图中的 A) |
readB |
蝶形运算的下输入索引(对应图中的 B) |
twiddle |
旋转因子,存储为 (cos, sin) |
WGSL 实现 (fftButterfly.wgsl):
struct Butterfly {
readA : u32, // 上输入的数组索引
readB : u32, // 下输入的数组索引
twiddle : vec2<f32>, // 旋转因子 (cos, sin)
}
@compute @workgroup_size(WORKGROUP_X, 1, 1)
fn main(@builtin(global_invocation_id) gid : vec3<u32>) {
let col = gid.x;
let stage = gid.y;
// ...
// 计算旋转因子 W_N^j = e^{i \pi j / stride}
let twiddle = vec2<f32>(cos(PI * f32(j) / f32(stride)), sin(PI * f32(j) / f32(stride)));
let r0 = stride * (i + 0u) + j; // 上半部分读取索引
let r1 = stride * (i + mid) + j; // 下半部分读取索引
// ...
butterfly[stage * map_size + w0] = Butterfly(r0, r1, twiddle);
butterfly[stage * map_size + w1] = Butterfly(r0, r1, -twiddle);
}FFT 核心逻辑
每一行的 FFT 通过多次迭代(stages)完成,使用共享内存 (Workgroup Shared Memory) 进行 ping-pong 双缓冲。
CPU 端调度 (JavaScript):
// dispatchWorkgroups(x, y, z)
pass.dispatchWorkgroups(1, mapSize, cascades * NUM_SPECTRA);
// x=1: 每行由一个 workgroup 处理
// y=mapSize: 共 mapSize 行
// z=cascades*4: 每个 cascade 有 4 个频谱通道WGSL 实现 (fftCompute.wgsl):
// 双缓冲共享内存:ping-pong 切换避免读写冲突
var<workgroup> row_shared : array<vec2<f32>, MAX_MAP * 2u>;
@compute @workgroup_size(MAX_MAP, 1, 1) // 每个 workgroup 处理一行
fn main(@builtin(global_invocation_id) gid : vec3<u32>, @builtin(local_invocation_id) lid : vec3<u32>) {
let col = lid.x; // 当前线程处理的列
let row = gid.y; // 当前行
let idx = row * map_size + col;
// Step 1: 从全局内存加载一行数据到共享内存
row_shared[col] = read_src(params.pingFrom, cascade, spectrum, map_size, idx);
// Step 2: 迭代执行 log2(N) 个 stage
var stage : u32 = 0u;
loop {
if (stage >= params.numStages) { break; }
workgroupBarrier(); // 必须同步,确保所有线程完成上一轮写入
let ping = stage & 1u; // 当前读取的缓冲区 (0 或 1)
let pong = (stage + 1u) & 1u; // 当前写入的缓冲区 (1 或 0)
// Step 3: 读取预计算的蝶形因子
let bfly = butterfly[stage * map_size + col];
// Step 4: 从共享内存读取两个输入(使用预计算的索引)
let upper = row_shared[ping * MAX_MAP + bfly.readA];
let lower = row_shared[ping * MAX_MAP + bfly.readB];
// Step 5: 蝶形运算 Y = A + B × W
row_shared[pong * MAX_MAP + col] = upper + mul_complex(lower, bfly.twiddle);
stage += 1u;
}
// Step 6: 写回全局内存
workgroupBarrier();
let final_ping = params.numStages & 1u;
let out_val = row_shared[final_ping * MAX_MAP + col];
write_dst(params.pingFrom, cascade, spectrum, map_size, idx, out_val);
}关键技术点:
- Ping-Pong 双缓冲:共享内存分成两半,交替读写,避免数据竞争
- Workgroup Barrier:确保所有线程完成当前 stage 才进入下一轮
- 预计算索引:
bfly.readA/readB决定了蝶形运算读取哪两个位置的数据 - 减法通过负旋转因子实现:预计算时,
w0位置存+W,w1位置存-W。所以代码中只写A + B×W,当W为负时自动变成A - B×|W|
矩阵转置 (Transpose)
为了对列执行 FFT,需要先将矩阵转置,这样可以保证 GPU 内存访问的连续性(coalesced access):
@compute @workgroup_size(WORKGROUP, WORKGROUP, 1)
fn main(@builtin(global_invocation_id) gid : vec3<u32>) {
let src_idx = idx(cascade, spectrum, gid.x, gid.y, map_size);
let dst_idx = idx(cascade, spectrum, gid.y, gid.x, map_size); // 交换 x 和 y
if (uni.useA == 1u) {
bufferB[dst_idx] = bufferA[src_idx];
} else {
bufferA[dst_idx] = bufferB[src_idx];
}
}2.4 解包与泡沫计算 (Unpack)
FFT 完成后,结果需要被解包并写入最终的渲染纹理。这一步还会计算雅可比行列式 (Jacobian) 来检测波浪翻卷(whitecaps/foam)。
Jacobian 与泡沫
Jacobian 行列式衡量了水平位移的压缩程度。当 时,表示水面发生了翻卷,应该出现泡沫:
WGSL 实现 (fftUnpack.wgsl):
@compute @workgroup_size(WORKGROUP, WORKGROUP, 1)
fn main(@builtin(global_invocation_id) gid : vec3<u32>) {
// ... 读取 FFT 结果 ...
// 写入位移贴图 (Displacement Map)
textureStore(displacementTex, vec2<u32>(gid.xy), gid.z, vec4<f32>(hxHy.x, hxHy.y, hzDhy.x, 0.0));
// 计算 Jacobian
let jacobian = (1.0 + dhx_dx) * (1.0 + dhz_dz) - dhz_dx * dhz_dx;
let foam_factor = -min(0.0, jacobian - params.foamTime.w); // foamTime.w = whitecap 阈值
// 泡沫衰减与累积
var foam = foamBuffer[foam_idx];
foam *= exp(-params.foamTime.z); // 衰减
foam += foam_factor * params.foamTime.y; // 增长
foam = clamp(foam, 0.0, 1.0);
foamBuffer[foam_idx] = foam;
// 写入法线/泡沫贴图
let gradient = vec2<f32>(dhy_dx, dhy_dz) / (1.0 + abs(vec2<f32>(dhx_dx, dhz_dz)));
textureStore(normalTex, vec2<u32>(gid.xy), gid.z, vec4<f32>(gradient, dhx_dx, foam));
}3. 渲染阶段详解
3.1 顶点着色器:位移采样
顶点着色器从位移贴图中采样,将平面网格的顶点在 Y 轴(高度)和 XZ 轴(水平)上进行偏移:
WGSL 实现 (waterSSS.wgsl - Vertex Shader):
@vertex
fn vs_main(@location(0) position : vec2<f32>) -> VSOut {
var displacement = vec3<f32>(0.0);
let num = uniforms.cascadeCount.x;
// 距离衰减:远处减小位移以避免 Z-fighting
let distanceFactor = min(exp(-(length(worldPosXZ - camPos.xz) - 500.0) * 0.007), 1.0);
// 叠加所有级联的位移
for (var i : u32 = 0u; i < num; i = i + 1u) {
let info = uniforms.cascades[i];
let uv = position.xy * info.uvScaleDisp.xy; // 根据 tile size 计算 UV
let sample = textureSampleLevel(displacementTex, displacementSampler, uv, i32(i), 0.0);
displacement += sample.xyz * info.uvScaleDisp.z; // 乘以位移缩放
}
let basePos = vec3<f32>(position.x, 0.0, position.y);
let worldPos = basePos + displacement * distanceFactor;
// ...
}3.2 片段着色器:PBR 光照与 SSS
片段着色器实现了完整的 PBR 光照模型,并加入了次表面散射 (SSS) 近似。
GGX 镜面反射
使用 GGX/Trowbridge-Reitz 微表面分布函数:
fn ggx_distribution(cos_theta : f32, alpha : f32) -> f32 {
let a_sq = alpha * alpha;
let d = 1.0 + (a_sq - 1.0) * cos_theta * cos_theta;
return a_sq / (PI * d * d);
}菲涅尔效应 (Fresnel)
视角越平行于水面,反射越强:
let fresnel = mix(pow(1.0 - n_dot_v, 5.0 * exp(-2.69 * baseRoughness)) / (1.0 + 22.7 * pow(baseRoughness, 1.5)), 1.0, REFLECTANCE);次表面散射近似 (SSS)
SSS 模拟光线穿过薄薄的波峰时的透射效果,使水面呈现出翡翠般的质感:
let sss_modifier = vec3<f32>(0.9, 1.15, 0.85); // SSS 使颜色偏绿
let sss_height = 1.0 * max(0.0, wave_height + 2.5) * pow(max(dot(lightDir, -viewDir), 0.0), 4.0) * pow(0.5 - 0.5 * dot(lightDir, normal), 3.0);
let sss_near = 0.5 * pow(n_dot_v, 2.0);
let water_contribution = (sss_height + sss_near) * sss_modifier / (1.0 + light_mask) + lambertian;
let diffuse_contribution = mix(water_contribution, uniforms.foamColor.rgb, foam_factor);双三次插值 (Bicubic Filtering)
为了法线贴图采样的平滑性,实现了 Bicubic B-Spline 滤波:
fn textureBicubic(tex : texture_2d_array<f32>, sampler : sampler, uvw : vec3<f32>) -> vec4<f32> {
// ... 使用 cubic_weights 计算权重 ...
return mix(
mix(textureSampleLevel(tex, sampler, vec2<f32>(h.yw), i32(uvw.z), 0.0),
textureSampleLevel(tex, sampler, vec2<f32>(h.xw), i32(uvw.z), 0.0), w.x),
mix(textureSampleLevel(tex, sampler, vec2<f32>(h.yz), i32(uvw.z), 0.0),
textureSampleLevel(tex, sampler, vec2<f32>(h.xz), i32(uvw.z), 0.0), w.x), w.y);
}4. 总结
本文详细解析了 Godot 风格海洋 FFT 实现的各个技术环节:
| 阶段 | 核心技术 |
|---|---|
| 频谱生成 | JONSWAP/TMA 频谱模型, Hasselmann 方向性函数 |
| 时间演化 | 色散关系, 复数乘法相位调制 |
| FFT 计算 | Stockham FFT, 蝶形因子预计算, 共享内存优化 |
| 矩阵转置 | 内存合并访问优化 |
| 解包 | Jacobian 泡沫检测, 泡沫累积与衰减 |
| 顶点着色 | 多级联位移叠加, 距离衰减 |
| 片段着色 | GGX 镜面反射, 菲涅尔效应, SSS 近似, Bicubic 滤波 |
这套实现完全运行在 GPU 上,充分利用了 WebGPU 的 Compute Shader 能力,可以实时渲染出高品质的海洋效果。