基于神经网络的辐射度缓存(Neural Radiance Caching)
基于神经网络的辐射度缓存(Neural Radiance Caching)

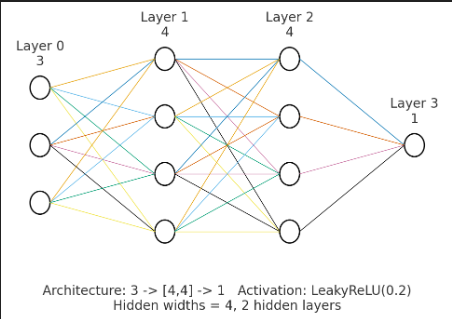
这是一个非常经典且巧妙的图形学方案,属于**基于神经网络的辐射度缓存(Neural Radiance Caching)或神经光照探针(Neural Light Probes)**的简化版本。
这个方案的核心思想是用一个极小的神经网络来替代传统的3D纹理或球谐函数(SH),用来存储一个大体积(8米体素)内的光照信息。
详细拆解这个方案的思路,并提供完整的训练代码(Python/PyTorch)和运行时代码(HLSL/GLSL Shader)。
1. 核心思路解析
问题背景
- 场景:远景全局光照(GI)。
- 痛点:如果用8m x 8m的大体素存一个光照值,精度太低,画面糊成一团。如果存高精度的3D纹理,显存爆炸。
- 目标:在不增加显存负担的情况下,让这个8m的大方块内部能表现出细腻的光照变化(比如屋檐下的阴影渐变)。
解决方案:函数拟合
不再存“像素点”,而是存一个“公式”。
认为空间中的光照分布是一个函数 。
- 输入:体素内的局部坐标 (x, y, z)。
- 输出:该点的亮度值 (Luminance)。
- 拟合工具:一个微型深度神经网络(DNN)。
网络架构 (根据文档)
- 结构:MLP (多层感知机)。
- 规模:2个隐藏层,每层宽度为4。
- 激活函数:Leaky ReLU ($\alpha=0.2$)。
- 参数量计算:
- 输入层(3) -> 隐藏层1(4):
- 隐藏层1(4) -> 隐藏层2(4):
- 隐藏层2(4) -> 输出层(1):
- 总参数:仅 41个浮点数!比存一张小贴图还小。
2. 离线训练部分 (Python & PyTorch)
虽然可以使用手动推导梯度的共轭梯度法(Conjugate Gradient),但在现代开发中,直接使用 PyTorch 最为方便快捷。
Step 1: 准备数据 & 定义网络
import torch
import torch.nn as nn
import torch.optim as optim
import numpy as np
import matplotlib.pyplot as plt
# 1. 定义微型神经网络 (按照文档描述)
class NeuralProbe(nn.Module):
def __init__(self):
super(NeuralProbe, self).__init__()
# 文档:2个隐藏层,宽度为4
# 输入: 3 (x, y, z)
# 隐藏层1: 4
self.fc1 = nn.Linear(3, 4)
# 隐藏层2: 4
self.fc2 = nn.Linear(4, 4)
# 输出: 1 (Luminance)
self.fc3 = nn.Linear(4, 1)
# 激活函数: Leaky ReLU (alpha=0.2)
self.act = nn.LeakyReLU(0.2)
def forward(self, x):
x = self.act(self.fc1(x))
x = self.act(self.fc2(x))
return self.fc3(x) # 输出层通常不加激活,或者加ReLU保证非负
# 2. 模拟 "烘焙" 数据 (Data Baking)
# 这一步在实际引擎中是光线追踪器生成的真实采样点
def get_fake_ground_truth_data(batch_size=5000):
# 随机生成局部坐标 [-4, 4] (假设8m体素)
x = (torch.rand(batch_size, 1) - 0.5) * 8.0
y = (torch.rand(batch_size, 1) - 0.5) * 8.0
z = (torch.rand(batch_size, 1) - 0.5) * 8.0
inputs = torch.cat([x, y, z], dim=1)
# 模拟一个复杂的遮挡关系(比如屋檐下)
# 假设 Y > 2.0 是屋檐下,比较黑;Y < 2.0 是亮的,中间有渐变
# 这是一个非线性的函数,用来测试神经网络的拟合能力
targets = torch.clamp(2.0 - y, 0.0, 1.0) * 0.8 + 0.1
# 添加一些噪声
targets += torch.randn_like(targets) * 0.01
return inputs, targets
# 3. 训练过程
def train():
model = NeuralProbe()
# 这里为了简单用Adam,文档提到的Conjugate Gradient适合C++手写求解器
optimizer = optim.Adam(model.parameters(), lr=0.01)
loss_fn = nn.MSELoss()
print("开始训练微型网络...")
# 训练很多个Epoch,因为网络很小,很容易欠拟合或陷入局部最优
for epoch in range(2000):
inputs, targets = get_fake_ground_truth_data(1000)
optimizer.zero_grad()
outputs = model(inputs)
loss = loss_fn(outputs, targets)
loss.backward()
optimizer.step()
if epoch % 200 == 0:
print(f"Epoch {epoch}, Loss: {loss.item():.6f}")
print("训练完成!")
return model
# 执行训练
trained_model = train()Step 2: 导出权重供 Shader 使用
训练好后,我们需要把 PyTorch 里的权重提取出来,变成 C++ 或 Shader 能读懂的数组。
def export_weights_for_shader(model):
weights = {}
# 提取每一层的权重和偏置
# 注意:PyTorch的Linear层权重形状是 (out_features, in_features)
# Shader中做矩阵乘法通常需要转置,或者按照特定顺序读取
print("\n--- Shader Parameters ---")
# Layer 1
w1 = model.fc1.weight.detach().numpy().T # 转置为 (3, 4)
b1 = model.fc1.bias.detach().numpy()
print(f"// Layer 1 Weights (3x4 Matrix):\nfloat4x3 W1 = {{ ... }};")
print(f"// Layer 1 Bias (float4):\nfloat4 b1 = float4({b1[0]:.4f}, {b1[1]:.4f}, {b1[2]:.4f}, {b1[3]:.4f});")
# Layer 2
w2 = model.fc2.weight.detach().numpy().T # 转置为 (4, 4)
b2 = model.fc2.bias.detach().numpy()
print(f"// Layer 2 Weights (4x4 Matrix)")
print(f"// Layer 2 Bias (float4)")
# Layer 3
w3 = model.fc3.weight.detach().numpy().T # 转置为 (4, 1)
b3 = model.fc3.bias.detach().numpy()
print(f"// Layer 3 Weights (4x1 Vector)")
print(f"// Layer 3 Bias (float)")
# 实际项目中,你会把这些数存进二进制文件或者Texture Buffer中
return w1, b1, w2, b2, w3, b3
export_weights_for_shader(trained_model)3. 运行时部分 (Shader 代码)
在运行时(Runtime),我们不需要反向传播,只需要前向推理(Inference)。由于网络极小,这可以直接在 Fragment Shader 或 Compute Shader 中通过简单的矩阵乘法实现。
GLSL / HLSL 伪代码实现:
假设我们把权重存入了 Uniform 变量或者 StructuredBuffer 中。
// HLSL
// --- 定义网络参数 (实际应用中这些通常来自 Constant Buffer 或 TextureLoad) ---
// 为了演示,这里写死,实际上应该由C#脚本传入
float4x3 W1; // 3行4列 (或者转置后存) - 输入层到隐层1
float4 b1;
float4x4 W2; // 4行4列 - 隐层1到隐层2
float4 b2;
float4 W3; // 权重向量 - 隐层2到输出
float b3; // 输出偏置
// --- Leaky ReLU 激活函数 ---
// LeakyReLU(x) = max(0.2 * x, x)
float4 LeakyReLU(float4 x) {
return max(0.2 * x, x);
}
// --- 核心推理函数 ---
// localPos: 相对于体素中心的坐标 (-4 到 +4)
float EvaluateNeuralProbe(float3 localPos) {
// 1. 第一层: Input(3) -> Hidden1(4)
// 矩阵乘法: 1x3 * 3x4 = 1x4
// 注意:根据你的矩阵存储方式,可能是 mul(W1, localPos) 或 mul(localPos, W1)
// 这里假设 W1 是列主序
float4 h1 = mul(localPos, W1) + b1;
h1 = LeakyReLU(h1);
// 2. 第二层: Hidden1(4) -> Hidden2(4)
float4 h2 = mul(h1, W2) + b2;
h2 = LeakyReLU(h2);
// 3. 输出层: Hidden2(4) -> Output(1)
// 点积操作
float luminance = dot(h2, W3) + b3;
// 确保亮度不为负 (可选)
return max(0, luminance);
}
// --- 在 Shader 中的调用 ---
float4 frag (v2f i) : SV_Target {
// 1. 获取世界坐标
float3 worldPos = i.worldPos;
// 2. 计算当前像素所在的体素中心 (假设体素大小为8米)
float3 voxelCenter = floor(worldPos / 8.0) * 8.0 + 4.0;
// 3. 获取局部坐标
float3 localPos = worldPos - voxelCenter;
// 4. (进阶) 如果场景里有很多体素,这里需要根据 voxel ID
// 从 Texture/Buffer 中加载对应的 W1, b1, W2... 等参数
// LoadNetworkWeights(voxelID, W1, b1, ...);
// 5. 计算光照
float giIntensity = EvaluateNeuralProbe(localPos);
return float4(giIntensity, giIntensity, giIntensity, 1.0);
}4. 进阶工程化实施方案
在实际游戏引擎(如Unity/Unreal)中落地时,你不会只训练一个网络,而是成千上万个体素。
数据结构 (Texture Packing):
- 一个体素需要 41 个 float。
- 你可以使用一张
RGFloat或RGBAFloat的纹理来存储这些权重。 - 每个体素占据纹理中的几行像素。
- 在 Shader 中,根据体素 ID 计算 UV 坐标,采样纹理来获取 W1, b1, W2...
训练管线:
- Baking (C++): 引擎内跑光追,在每个8m体素内生成 1000~5000 个采样点 (Pos, GI)。
- Training (Python/C++): 导出数据,用脚本批量训练这几千个小网络。由于网络极小,训练速度极快。
- Packing: 将训练好的权重打包成二进制文件或纹理资源。
性能优化:
- 文档中提到的共轭梯度法 (Conjugate Gradient) 是为了在 C++ 端直接求解最优权重,避免依赖庞大的 PyTorch 库。对于这种简单的“凸优化”或类凸优化问题,传统数学方法可能比 SGD/Adam 更快收敛,且易于集成到烘焙工具中。
- FP16: 运行时完全可以用半精度 (half/min16float) 计算,因为只是远景 GI,对精度要求不高,性能翻倍。
总结
这个方案的本质是有损压缩。它用 41 个浮点数(函数参数)通过算力换显存,压缩了原本需要几千个字节才能存储的 3D 空间光照信息。
这段代码是 PyTorch(以及大多数深度学习框架)训练神经网络时的标准五步曲。
你可以把这五行代码看作是教学生(神经网络)做题的一个完整循环。
为了方便理解,我们结合你这个“光照探针”的场景,用一个**“射击打靶”**的比喻来解释。
- 模型(Model):一个蒙着眼睛的射手(或者一个刚开始什么都不懂的学生)。
- 输入(Inputs):靶子的位置(XYZ坐标)。
- 目标(Targets):靶心真正的光照强度(正确答案)。
- 损失(Loss):射出的子弹偏离靶心有多远(误差)。
解释
下面逐行拆解:
1. optimizer.zero_grad()
【归零 / 清空记忆】
- 代码含义:把优化器里所有参数的“梯度”(Gradient)全部清零。
- 为什么要这么做?
- PyTorch 有一个机制:默认会累加梯度。如果你不归零,第二次训练计算出的梯度会叠加上第一次的梯度,第三次会叠加前两次的……这样方向就全乱了。
- 比喻:射手在上一轮射击时,教练告诉他“手往左偏一点”。在开始下一轮射击前,射手必须先把脑子里的这个“旧指令”忘掉,否则他会基于旧指令再叠加新指令,最后动作就变形了。
- 一句话:“把之前的账清空,这轮算这轮的。”
2. outputs = model(inputs)
【前向传播 / 猜答案】
- 代码含义:把输入数据(体素内的 XYZ 坐标)喂给神经网络,让网络算出一个预测结果(亮度值 Luminance)。
- 场景结合:网络接收坐标
(0.5, 0.1, -0.5),经过层层计算,瞎猜了一个亮度值0.8。 - 比喻:射手凭感觉开了一枪。或者学生在考卷上填了一个他认为对的答案。
3. loss = loss_fn(outputs, targets)
【计算误差 / 对答案】
- 代码含义:拿着模型猜出的结果(outputs)和真实的标准答案(targets)进行对比,算出一个分数(Loss)。
- 场景结合:
- 猜的亮度:
0.8 - 真实烘焙的亮度:
0.3 - 误差(Loss):
(0.8 - 0.3)^2 = 0.25(假设是均方误差)。
- 猜的亮度:
- 比喻:报靶员跑过去看了一眼,大喊:“偏了!离靶心差了十万八千里!”。或者老师批改作业,发现答案错了,扣了分。
4. loss.backward()
【反向传播 / 找原因】
- 代码含义:这是深度学习最核心的魔法(链式法则)。它从 Loss 开始往回推,计算网络中每一个参数(权重 W 和偏置 b)对这个错误负多大责任。
- 结果:它会算出每个参数的梯度(Gradient)。梯度就是告诉参数:“你需要变大一点”还是“变小一点”才能让误差变小。
- 比喻:教练通过分析弹着点,逆向推导动作问题:“这一枪打偏,是因为你手肘抬高了 2 毫米,且手腕向右抖了 1 度。”
- 它只负责找原因和计算修正方案,但此时还没有真正修改参数。
5. optimizer.step()
【参数更新 / 修正动作】
- 代码含义:根据刚才
backward()算出来的梯度,真正的去修改网络里的权重参数。 - 公式:
新参数 = 旧参数 - 学习率 * 梯度。 - 比喻:射手听了教练的话,真正地调整了自己的肌肉和姿势,准备下一轮射击。
总结这个循环
想象你在教一个瞎子投篮:
zero_grad:深呼吸,忘掉上一次投篮的感觉。model(inputs):出手投篮!(得到结果)loss_fn:听到球“哐”的一声砸在篮板边缘(计算偏差)。backward:大脑快速分析:声音偏右了,说明刚才手用力过猛且偏右了(计算修正量)。step:调整手臂肌肉,下次投篮时往左修正一点,力度小一点(应用修正)。
这个循环在训练中会重复几千次(Loop),直到模型每次都能投进空心球(Loss 变得非常小)。